Validation and psychometric properties
Validation is an ongoing process of testing an instrument in different ways and in different contexts to determine whether or not the instrument measures what it purports to measure.
Both the descriptive system and the utility values associated with health states require validation. More specifically the descriptive system should be shown to have content, construct and criterion validity. Utility scores should correctly reflect the strength of people's preference for health states. As well, the model employed to combine the utility scores from different dimensions should also be valid.
Yes. Using the time trade-off (TTO) instrument a person might think the health state being evaluated represents very poor health and readily trade off years of life. Rather than live for their full 10 remaining years in the poor health state, they would readily live for 1 year in full health and trade off 9 years. It is appropriate at such a low number of years to ask whether the person would prefer death rather than live any time in the health state. When the answer is affirmative, a Worse-than-Death TTO question is asked: If there still remained 10 years of life, what is the maximum time the person could live in the poor health state if they knew there would be a cure which would restore them to full health for the remainder of the 10 years. Placing a numerical value on these states is difficult. If a person refused even one day in the health state followed by 10 years of full health the implied numerical value of the health state is almost minus infinity. This problem is discussed at length in Richardson and Hawthorne (2001) and various options are discussed and their numerical implications demonstrated. The final algorithm used for the calculation of utilities transforms negative scores in such a way that the lower boundary is U = -0.25; that is there is a disutility of 1.25.
This involves two separate issues.
Validating scaling techniques is problematical as it is not possible to observe actual trade-offs between the quality and length of life which correspond with the trade-offs measured by the various scaling instruments. Consequently, validity has been determined primarily by face validity. Some have argued that the standard gamble should be regarded as the gold standard for utility measurement as its use assumes the axioms of von Neumann & Morgenstern; this appears to make the standard gamble results consistent with mainstream economic theory. However, as the axioms have been shown to be empirically incorrect we have not adopted this procedure (Pope CHE Working Paper). Rather, for the reasons outlined by Richardson (1994) and Dolan et al (1996), we have accepted the time trade off as having the greatest prima facie validity.
No. The AQoL is the only instrument whose descriptive system was constructed using correct psychometric principles for instrument construction. Most instruments in the literature claim validation on the basis of a correlation between results and results from another instrument which has been validated (often in the same way!). This type of result is necessary but far from sufficient for confidence in an instrument. A valid instrument will produce valid utility scores. The criterion for achieving this is, in fact, exceedingly stringent. The percentage increase in the numerical score of the utility index must indicate an increase in the quality of life which is valued equally to an identical percentage increase in the length of life. No instrument has been shown to have this property. For a discussion of this so called strong interval property see Richardson Working Paper 5 (1990) Cost utility analysis: what should be measured. Importantly, an instrument may be valid in one context (disease area, intervention) but not in another.
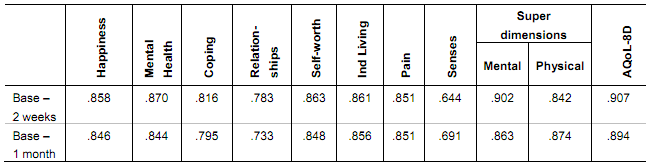
This table provides intraclass correlation coefficients for the instrument and its dimensions for reapplication of the AQoL8D instrument after two weeks and after one month.
Table 3 Test-Retest reliability: intra class correlation coefficients (ICC)
Test-retest reliability coefficients are sourced from J Richardson, A Iezzi (2011). Psychometric validity and the AQoL 8D Multi attribute utility instrument. Research Paper 71, Table 3, p13.
The AQoL- 4D measures 1.07 billion health states which is a very small subset of the number of health states defined by AQoL- 8D (many of which are a little improbable, eg being blind, deaf, bedridden, full of energy and in control of your life). These health states cannot all be measured individually and, like all other MAU instruments (except for the Rosser-Kind index) AQoL models utility scores from a limited number of observations. To date, most instruments have adopted an additive model in which the disutility associated with each response from each item is independently measured, and the overall disutility estimated or modelled as a weighted average of these disutilities, where the weights are also obtained empirically during the scaling survey. This additive model is probably invalid and the multiplicative model employed by the HUI and AQoL instruments is superior (Richardson & Hawthorne 1998). However there is no certainty that even this more flexible model does not introduce significant estimation bias. |
|